TikTak Global Optimizer
This page contains information and codes for the TikTak Global Optimization algorithm. TikTak is a very efficient, reliable, and asynchronously parallel algorithm that is easy to use. In particular:
It has very strong single-core performance (as measured by speed and reliability) against several popular global optimization algorithms. See Arnoud, Guvenen, and Kleineberg (2022), which benchmarks TikTak and 7 other popular global optimizers on well-known test functions as well as on a simulated method of moments (SMM) estimation problem.
The code is written to be run in parallel mode out of the box, without requiring any specialized software (MPI, OpenMP, etc.). It can be run both on computer clusters and on fully distributed mixed computational environments by only using a syncing solution like DropBox. For example, the code can be easily run in parallel on a PC workstation in Europe and a Mac Pro in the United States. Furthermore, the code allows asynchronously parallel use: new cores can be added or terminated during runtime without problems.
For medium- to large-scale problems, its parallel performance scales almost linearly with the number of cores–see below.
The description of the basic algorithm can be found in Arnoud, Guvenen, and Kleineberg (2022). However, the implementation posted below contains crucial efficiency improvements relative to that version.
Parallel Performance
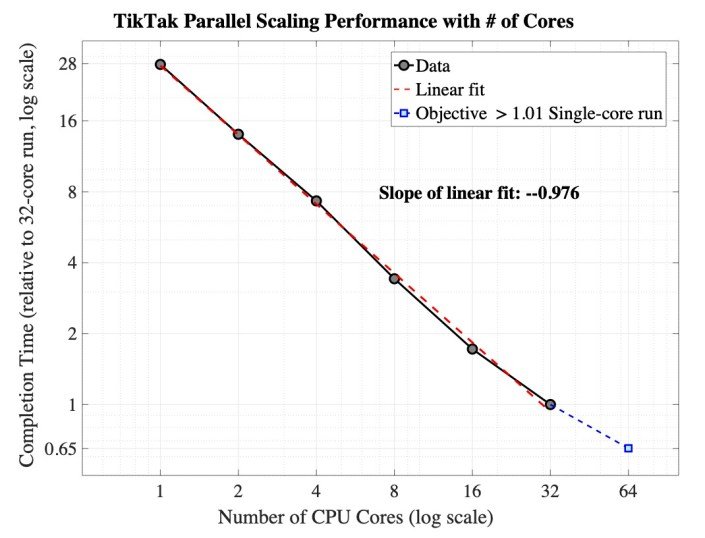
Here is an example of the scaling performance of TikTak on a Simulated Method of Moments estimation problem with 1200+ moments and 7 parameters (taken from Guvenen, Karahan, Ozkan, Song (ECMA, 2021, specification in Table IV, column 2).
The figure below shows the completion time of TikTak against the number of cores used in parallel, with the condition that the objective attained is always within 1% of the single-core value. The log-log plot is almost linear from 1 to 32 cores, with a slope of -0.976, showing almost linear scaling. Doubling the number of cores from 32 to 64 yields a final objective value that exceeds the 1% threshold (at 1.8%).
The estimation required about N=1000 restarts (or local optimizations) in the global stage, so these results suggest a heuristic: #core ≤ √N (√1000 ≈ 32), for the number of cores that can be used in parallel with linear scaling and no performance degradation. (Although we found that in this example, using 50 cores still delivered linear scaling without slowdown, so further experimentation is recommended).
TikTak Code and Further Information:
ReadMe page for the code package: README
The latest version of the code package is posted on Serdar Ozkan’s Github: GitHub Link
If you use the TikTak code and find it helpful, please drop us a line. Knowing the user base can help us with future revisions.
To report a bug or send comments, email us at serdarozkan@gmail.com and fatihguvenen@gmail.com.